


안녕하세요. 오늘은 자바 가상 머신(JVM)에 대해 공부한 내용을 정리하려고 합니다. JVM은 Java 프로그램이 운영체제에 종속되지 않고 실행될 수 있도록 해주는 중요한 역할을 담당하고 있는데요. 이 포스팅에서는 JVM의 구조와 Class가 JVM에 로딩되는 과정에 대해 알아보도록 하겠습니다.
JVM
C나 C++과 같은 언어로 작성된 프로그램은 컴파일된 실행 파일이 특정 운영체제에서만 동작합니다. 예를 들어, Linux에서 컴파일된 프로그램은 Windows에서 실행되지 않습니다. 이러한 플랫폼 종속성을 해결하려면 크로스 컴파일(Cross Compile)이나 별도의 컴파일러가 필요합니다.
Java는 JVM을 통해 이러한 플랫폼 종속성을 해결합니다. JVM(Java Virtual Machine)은 자바 바이트코드를 각 운영체제에 맞게 해석하고 실행해주는 가상 머신입니다. 이를 통해 Java 프로그램은 "한 번 작성하면, 어디서든 실행된다 (Write Once, Run Anywhere)"는 특징을 가질 수 있습니다. 즉, 자바 가상 머신이 각 운영체제에 종속된 차이를 흡수해주는 역할을 함으로써 다양한 운영체제에서 자바 프로그램을 동일하게 실행할 수 있게 되는 것이죠.

여기서 잠깐 !
자바 가상 머신이라면 당연히 자바 프로그램을 실행한다고 생각할 수 있지만 자바 기술은 초기 설계부터 가상 머신에서 다른 언어를 실행할 가능성을 염두해 두었습니다. 1997년에 발표한 최초의 《자바 가상 머신 명세》 에서는 "미래에는 다른 언어들을 더 잘 지원하도록 자바 가상 머신을 확장할 것이다(In the future, we will consider bounded extensions to the Java virtual machine to provide better support for other languages)"라고 명시했습니다. 그 후 2018년에는 핫스팟을 확장한 그랄 VM을 발표하면서 이 약속을 지키게 됩니다.

Java Application 실행 과정
이제 자바 애플리케이션이 JVM에서 어떻게 실행되는지 하나씩 살펴보겠습니다.
- 애플리케이션이 실행되면, 가장 먼저 JVM이 OS로부터 필요한 메모리를 할당받습니다. 이 메모리는 프로그램이 안정적으로 실행되기 위한 기반을 마련해 주는 역할을 합니다.
- 다음으로 자바 컴파일러(`javac.exe`)가 자바 소스 코드(`.java` 파일)를 읽어들여 바이트 코드(`.class` 파일)로 변환합니다. 바이트 코드는 JVM이 이해할 수 있는 형태로 변환된 코드라고 할 수 있습니다.
- 변환된 바이트 코드는 이제 Class Loader에 의해 JVM 내부로 로딩됩니다. Class Loader는 JVM에서 바이트 코드를 찾아 로드하는 일을 담당하며, 애플리케이션 실행을 위한 필수적인 작업을 수행합니다.
- 로딩된 바이트 코드는 Execution Engine이라는 실행 엔진을 통해 한 줄씩 해석되며 실행됩니다. Execution Engine은 바이트 코드를 실제로 실행 가능한 형태로 바꿔주는 역할을 합니다.
- 마지막으로 해석된 바이트 코드는 Runtime Data Area에 배치되어 실행되며, 이 과정에서 JVM의 Garbage Collection(GC)도 함께 이루어져 메모리 관리가 자동으로 진행됩니다.
JVM 구조

JVM이 자바 애플리케이션을 어떻게 실행하는지 이해하려면, 각 구성 요소가 어떤 역할을 하는지 알아두는 것이 중요합니다. 이제 네 가지 주요 부분을 중심으로 JVM의 구조를 하나씩 살펴보겠습니다.
- 클래스 로더 시스템 (Class Loader System): 자바 바이트 코드를 찾아 로드하여 JVM에 필요한 클래스를 올려주는 역할을 합니다.
- 실행 엔진 (Execution Engine): 로드된 바이트 코드를 실제로 실행할 수 있는 형태로 변환해 주는 중요한 부분입니다.
- 런타임 데이터 영역 (Runtime Data Area): 프로그램 실행에 필요한 데이터를 저장하며, 메모리 관리가 이루어지는 공간입니다.
- 네이티브 메서드 인터페이스 및 라이브러리 (Native Method Interface, Native Method Libraries): JVM이 운영체제의 기본 기능과 상호작용할 수 있도록 돕는 역할을 합니다.
간단히 살펴본 내용만으로는 각 구성 요소의 역할이 충분히 와닿지 않을 수 있습니다. 이해를 돕기 위해 각 구성 요소가 자바 애플리케이션 실행에 어떻게 기여하는지 더 깊이 알아보겠습니다.
클래스 로더 시스템 (Class Loader System)
클래스 로더는 자바 언어의 혁신이라고 할 수 있는데요. 초기에 자바 언어가 빠르게 보급된 주된 이유이기도 합니다. 클래스 로더는 원래 자바 애플릿을 위해 설계되었지만 자바 애플릿을 지원하는 브라우저는 현재 사라진 상태입니다.
자바 가상 머신 설계진은 필요한 클래스를 얻는 방법을 애플리케이션이 정할 수 있기를 원했습니다. 그래서 클래스 로딩 단계 중 '완전한 이름을 보고 해당 클래스를 정의 하는 바이너리 바이트 스트림 가져오기'를 가상 머신 외부에서 수행하도록 하였습니다. 이 역할을 맡은 코드를 클래스 로더라고 합니다. 더 쉽게 설명하자면

그림을 통해 알 수 있듯이 Java 컴파일러(javac.exe)를 통해 .java 파일이 바이트 코드(.class 파일)로 변환되면, 이 바이트 코드를 JVM으로 로딩하는 역할을 클래스 로더 시스템이 담당합니다.
클래스 로더 시스템은 Java 프로그램이 사용하는 클래스를 메모리에 로드하는 과정을 관리합니다. JVM은 프로그램을 처음 시작할 때 모든 클래스를 메모리에 올리지 않고, 필요할 때 로드하는 '지연 로딩(lazy loading)' 방식을 사용하는데요. 이때 로딩(Loading), 링크(Linking), 초기화(Initialization) 이 세 단계의 과정을 거친 후 클래스가 JVM의 메모리 영역인 Runtime Data Area에 배치됩니다.

로딩 (Loading)
로딩 단계에서는 `.class` 파일을 찾고 메모리에 올립니다. 이때 로딩 기능은 한 번에 메모리에 올리지 않고, 어플리케이션에서 필요한 경우 동적으로 메모리에 적재합니다. 로딩 단계에서는 부트스트랩, 플랫폼, 애플리케이션 클래스 로더가 계층적으로 클래스 파일을 찾는데요. 쉽게 설명하면 클래스 로더들은 위임 모델을 따르며, 클래스 로딩 요청을 받으면 먼저 상위 로더에게 로딩을 위임하여 최상위인 `Bootstrap Class Loader`부터 차례로 탐색한다는 뜻입니다.
- 부트스트랩 클래스 로더 (Bootstrap Class Loader)
부트스트랩 클래스 로더는 가장 기본적인 클래스를 로드하는 로더로서, Java 코어 라이브러리(`java.lang`, `java.util` 등)를 메모리에 올리는 역할을 합니다. 이 로더는 `JAVA_HOME/lib` 디렉터리나 `-Xbootclasspath` 매개변수로 지정된 경로에 위치한 파일들, 즉 JVM이 클래스 라이브러리로 인식하는 파일들(`rt.jar`, `tools.jar` 등)을 로드하는 책임을 맡고 있습니다. 부트스트랩 클래스 로더는 자바 프로그램에서 직접 참조할 수 없으며, 커스텀 클래스 로더를 작성할 때 로딩을 부트스트랩 클래스 로더에 위임하고자 하면 참조 대신 `null`을 사용합니다.
- 플랫폼(확장) 클래스 로더 (Platform Class Loader)
플랫폼 클래스 로더는 `javax`, `jdk` 등과 같은 플랫폼 관련 라이브러리를 로드합니다. 최신 JVM에서는 Extension Class Loader라는 용어 대신 Platform Class Loader를 사용하는데요. 이 로더는 `sun.misc.Launcher$ExtClassLoader`로 구현되어 있으며, `JAVA_HOME/lib/ext` 디렉터리나 `java.ext.dirs` 시스템 변수로 지정된 경로의 클래스 라이브러리들을 로드하는 역할을 합니다.
이름에서 알 수 있듯이, 자바 시스템의 클래스 라이브러리를 확장하는 메커니즘으로 사용됩니다. 하지만 JDK 9부터는 모듈 시스템을 통한 확장 메커니즘으로 대체되었습니다. 플랫폼 클래스 로더는 자바 코드로 구현되었기 때문에 개발자가 프로그램 내에서 직접 사용할 수 있습니다.
- 애플리케이션 클래스 로더 (Application Class Loader)
애플리케이션 클래스 로더는 사용자가 작성한 모든 클래스를 `classpath`에서 로드합니다. 프로그램의 대부분의 클래스 파일이 이 로더를 통해 로드되며, `sun.misc.Launcher$AppClassLoader`로 구현되어 있습니다. `ClassLoader` 클래스의 `getSystemClassLoader()` 메서드가 반환하는 클래스 로더라는 의미에서 시스템 클래스 로더라고도 합니다. 개발자가 자바 코드에서 직접 사용할 수 있으며, 애플리케이션에서 별도의 클래스 로더를 만들지 않는 한 기본적으로 이 로더가 사용됩니다.
자바 모듈 시스템의 세 가지 클래스 로더는 각각 다음 모듈을 담당합니다.
- 부트스트랩 클래스 로더가 담당하는 모듈:
| java.base | java.security.sasl |
| java.datatransfer | java.xml |
| java.desktop | jdk.httpserver |
| java.instrument | jdk.internal.vm.ci |
| java.loggin | jdk.management |
| java.management | jdk.management.agent |
| java.management.rmi | jdk.naming.rmi |
| java.naming | jdk.net |
| java.prefs | jdk.sctp |
| java.rmi | jdk.unsupported |
- 플랫폼 클래스 로더가 담당하는 모듈:
| java.activation* | jdk.accessibility |
| java.compiler* | jdk.charsets |
| java.corba* | jdk.crypto.cryptoki |
| java.scripting | jdk.crypto.ec |
| java.se | jdk.dynalink |
| java.se.ee | jdk.incubator.httpclient |
| java.security.jgss | jdk.internal.vm.compiler* |
| java.smartcardio | jdk.jsobject |
| java.sql | jdk.localedata |
| java.sql.rowset | jdk.naming.dns |
| java.transaction* | jdk.scripting.nashorn |
| java.xml.bind* | jdk.security.auth |
| java.xml.crypto | jdk.security.jgss |
| java.xml.ws* | jdk.xml.dom |
| java.xml.ws.annotation* | jdk.zipfs |
- 애플리케이션 클래스 로더가 담당하는 모듈:
| jdk.aot | jdk.jdeps |
| jdk.attach | jdk.jdi |
| jdk.compiler | jdk.jdwp.agent |
| jdk.editpad | jdk.jlink |
| jdk.hotspot.agent | jdk.jshell |
| jdk.interanl.ed | jdk.jstatd |
| jdk.internal.jvmstat | jdk.pack |
| jdk.internal.le | jdk.policytool |
| jdk.internal.opt | jdk.rmic |
| jdk.jartool | jdk.scripting.nashorn.shell |
| jdk.javadoc | jdk.xml.bind* |
| jdk.jcmd | jdk.xml.ws* |
| jdk.jconsole |
이처럼 각 클래스 로더는 자신이 담당하는 모듈을 통해 필요한 클래스를 로딩합니다. 하지만 실제로 클래스 로딩 과정은 각 로더가 독립적으로 동작하는 것이 아니라, 서로 협력하여 이루어집니다.
바로 여기에서 중요한 역할을 하는 것이 클래스 로더의 '위임 모델'입니다. 클래스 로더들은 어떻게 서로 협력하고, 로딩 요청을 처리할까요?
클래스 로더 위임 과정
클래스 로더들은 부모 위임 모델을 통해 서로 협력하며, 이 과정은 다음과 같은 단계로 이루어집니다.

- 클래스 필요 시점: 프로그램 실행 중 특정 클래스가 필요하게 되면, JVM은 애플리케이션 클래스 로더에게 해당 클래스를 로드하라는 요청을 보냅니다.
- 상위 로더에게 위임: 애플리케이션 클래스 로더는 요청을 바로 처리하지 않고, 상위 로더인 플랫폼 클래스 로더에게 로딩 작업을 위임합니다.
- 최상위 로더에게 위임: 플랫폼 클래스 로더는 다시 부트스트랩 클래스 로더에게 요청을 전달하여, 가장 최상위 클래스 로더가 먼저 클래스를 찾도록 합니다.
- 부트스트랩 클래스 로더의 탐색: 부트스트랩 클래스 로더는 JVM 표준 라이브러리(Java API)에서 해당 클래스를 찾습니다. 만약 클래스를 찾지 못하면, 플랫폼 클래스 로더에게 제어를 넘겨줍니다.
- 플랫폼 클래스 로더의 탐색: 플랫폼 클래스 로더는 자신의 클래스 경로에서 클래스를 찾습니다. 여기서도 찾지 못하면, 애플리케이션 클래스 로더로 요청이 넘어갑니다.
- 애플리케이션 클래스 로더의 탐색: 애플리케이션 클래스 로더는 최종적으로 사용자 정의 클래스나 외부 라이브러리에서 클래스를 로드합니다.
- 클래스 로드 실패 시: 만약 애플리케이션 클래스 로더까지 클래스를 찾지 못하면, JVM은 `ClassNotFoundException`이나 `NoClassDefFoundError`를 발생시킵니다. 여기서 `NoClassDefFoundError`는 이미 한 번 로드되었던 클래스가 다시 로드되지 못하는 경우에 발생합니다.
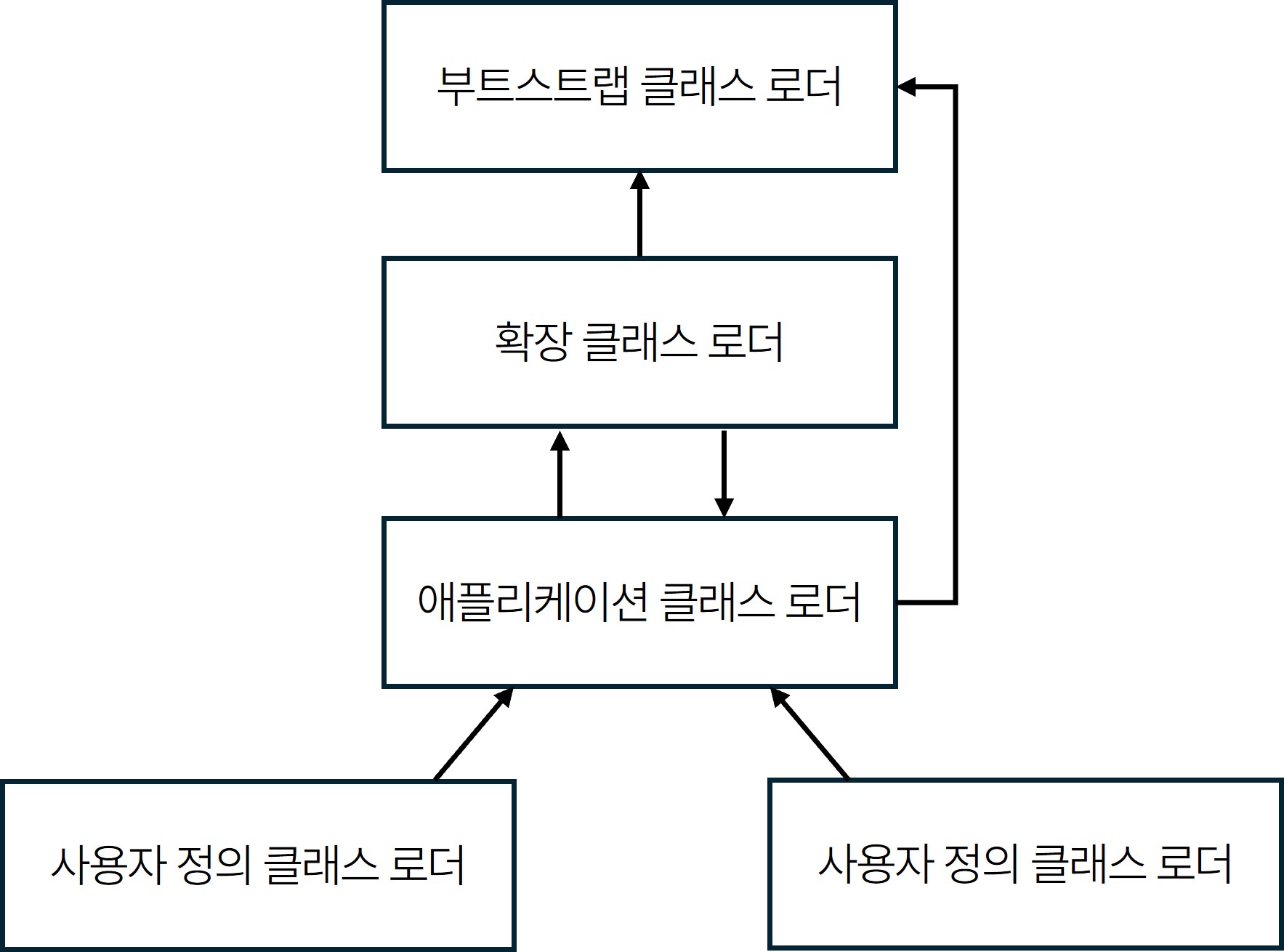
JDK 9부터는 모듈 시스템의 도입으로 인해 클래스 로더의 동작 방식에 변화가 생겼습니다. 플랫폼 및 애플리케이션 클래스 로더는 클래스를 로딩할 때 다음과 같은 절차를 따릅니다.
- 클래스 필요 시점: 프로그램 실행 중 특정 클래스가 필요하게 되면, 해당 클래스가 어떤 모듈에 속하는지 확인합니다.
- 모듈 의존성 확인: 클래스가 특정 시스템 모듈에 속한다면, 그 모듈을 담당하는 로더에게 직접 로딩을 요청합니다.
- 부모 위임 모델 적용: 클래스가 특정 모듈에 속하지 않는다면, 기존의 부모 위임 모델에 따라 부모 로더에게 로딩을 위임합니다.
- 클래스 로드 실패 시: 필요한 클래스를 끝까지 찾지 못하면 `ClassNotFoundException`이나 `NoClassDefFoundError`를 발생시킵니다
이제 실제로 작성한 Class를 Application Class Loader에서 로드하는지 직접 확인해보겠습니다.
public class App {
public static void main(String[] args) {
ClassLoader classLoader = App.class.getClassLoader();
System.out.println(classLoader);
System.out.println(classLoader.getParent());
System.out.println(classLoader.getParent().getParent());
}
}
--------------------------------------------------------------------------------------------
jdk.internal.loader.ClassLoaders$AppClassLoader@36baf30c
jdk.internal.loader.ClassLoaders$PlatformClassLoader@b4c966a
null
이 코드의 출력 결과를 통해 Application Class Loader와 그 부모 클래스 로더(Platform Class Loader)를 확인할 수 있습니다.
Platform Class Loader의 부모 최상위 Bootstrap Class Loader는 네이티브 코드로 구현되어 있기 때문에, 자바 코드에서 직접 참조 할 수 없어 `null`이 출력되는 것을 알 수 있습니다. 그리고 실제 Platform Class Loader 내부를 살펴보면 다음과 같이 여러 클래스 로더의 이름이 선언되어 있는 것을 알 수 있습니다.
static {
ArchivedClassLoaders archivedClassLoaders = ArchivedClassLoaders.get();
if (archivedClassLoaders != null) {
// assert VM.getSavedProperty("jdk.boot.class.path.append") == null
BOOT_LOADER = (BootClassLoader) archivedClassLoaders.bootLoader();
setArchivedServicesCatalog(BOOT_LOADER);
PLATFORM_LOADER = (PlatformClassLoader) archivedClassLoaders.platformLoader();
setArchivedServicesCatalog(PLATFORM_LOADER);
} else {
// -Xbootclasspath/a or -javaagent with Boot-Class-Path attribute
String append = VM.getSavedProperty("jdk.boot.class.path.append");
URLClassPath ucp = (append != null && !append.isEmpty())
? new URLClassPath(append, true)
: null;
BOOT_LOADER = new BootClassLoader(ucp);
PLATFORM_LOADER = new PlatformClassLoader(BOOT_LOADER);
}
// A class path is required when no initial module is specified.
// In this case the class path defaults to "", meaning the current
// working directory. When an initial module is specified, on the
// contrary, we drop this historic interpretation of the empty
// string and instead treat it as unspecified.
String cp = System.getProperty("java.class.path");
if (cp == null || cp.isEmpty()) {
String initialModuleName = System.getProperty("jdk.module.main");
cp = (initialModuleName == null) ? "" : null;
}
URLClassPath ucp = new URLClassPath(cp, false);
if (archivedClassLoaders != null) {
APP_LOADER = (AppClassLoader) archivedClassLoaders.appLoader();
setArchivedServicesCatalog(APP_LOADER);
APP_LOADER.setClassPath(ucp);
} else {
APP_LOADER = new AppClassLoader(PLATFORM_LOADER, ucp);
ArchivedClassLoaders.archive();
}
}

링크 (Linking)
가상 머신의 메모리에 로드되는 걸 시작으로 다시 언로드될 때까지 로딩 → 검증 → 준비 → 해석 → 초기화 → 사용 → 언로딩 과정을 거치는데 이 중 검증, 준비, 해석 단계를 묶어 링킹이라고 합니다. 그림에서 로딩, 검증, 준비, 초기화, 언로딩은 반드시 순서대로 진행해야 합니다. 반면 해석 단계는 때에 따라서 초기화 후에 시작할 수 있습니다. 자바 언어의 런타임 바인딩(동적 바인딩)을 지원하기 위해서입니다.
참고로 여기서 단계별 순서의 기준은 '진행'이나 '완료' 시점이 아니라 '시작'지점입니다.
링크 단계에서는 로드된 클래스 파일이 올바르게 작성되었는지 확인하고 사용할 준비를 하는데요. 이때 링크 과정은 세 가지 단계로 나누어집니다.
- 검증(Verification)
검증 단게에서는 크게 다음 4단계를 거쳐 완료됩니다.
- 파일 형식 검증
- 메타데이터 검증
- 바이트코드 검증
- 심벌 참조 검증
각각을 차례로 자세히 알아보자면 첫 번째 단계에서는 바이트 스트림이 클래스 파일 형식에 부합하고 현재 버전의 가상 머신에서 처리될 수 있는지 확인합니다. 두 번째로 바이트 코드로 설명된 정보의 의미를 분석하여 서술된 정보가 《자바 언어 명세》의 요구 사항을 충족하는지 확인합니다. 바이트코드 검증은 전체 검증 과정에서 가장 복잡한 단계로 이 단계의 주된 목적은 데이터 흐름과 제어 흐름을 분석하여 프로그램의 의미가 적법하고 논리적인지 확인하는 것입니다. 이 단계에서는 클래스의 메서드 본문(클래스 파일의 Code 속성)을 분석합니다. 메서드가 런타임에 가상 머신의 보안을 위협하는 동작을 하지 않는지 확인하는 것입니다. 검증의 마지막 단계는 가상 머신이 심벌 참조를 직접 참조로 변환할 때 수행됩니다. 이 변환은 링킹의 세 번째 단계인 해석 단계에서 일어나는데, 심절 참조 검증은 해당 클래스 자체(상수 풀의 다양한 심벌 참조)를 제외한 모든 정보를 화인하는 것으로 보면 됩니다. 쉽게 이야기하면 현재 클래스가 참조하는 특정 외부 클래스, 메서드, 필드, 그 외 자원들에 접근할 권한이 있는지 확인합니다. 심벌 참조 검증의 주된 목적은 해석을 제대로 수행할 수 있는지 확인하는 것입니다. 심벌 참조 검증을 통과하지 못하면 자바 가상 머신이 `IncompatibleClassChangeError`의 하위 예외를 던집니다.(`IllegalAccessError`, `NoSuchFieldError`, `NoSuchMethodError `등.) 검증 단계는 매우 중요하지만 필수는 아니기 때문에 프로그램에서 실행하는 모든 코드를 신뢰할 수 있다면 프로덕션 환경에서 실행할 때는 검증을 건너뛰기도 합니다.(`-Xverify:none` 매개 변수 지정) 검증을 생략하면 가상 머신이 클래스를 로딩하는 시간이 단축됩니다. 간단하게 검증 단계를 설명하자면 검증 단계에서는 `.class` 파일의 형식과 구조가 올바른지 체크하고 이 과정에서 문제가 발견되면 JVM은 실행을 중단한다고 설명할 수 있습니다.
- 준비(Preparation)
준비는 클래스 변수(정적 변수)를 메모리에 할당하고 초깃값을 설정하는 단계로 개념적으로는 이 변수들이 사용하는 메모리를 메서드 영역에 할당해야 하지만, 메서드 영역 자체가 논리적 영역임을 감안해야 합니다. 준비 단계에서는 혼란스러운 개념이 두 가지 등장하는데 첫째, 인스턴스 변수가 아닌 클래스 변수만 할당이 됩니다. 인스턴스 변수는 객체가 인스턴스화 될 때 객체와 함께 자바 힙에 할당이 됩니다. 둘째, 준비 단계에서 클래스 변수에 할당하는 초깃값은 해당 데이터 타입의 제로 값입니다. 예를 들어
public static int value = 123;
자바 코드에서 클래스 변수를 다음과 같이 정의했다고 해 보면 준비 단계를 마친 직후 value 변수에 할당되어 있는 초깃값은 123이 아닌 0입니다. 123을 할당하는 일은 '클래스 초기화 단계'에 가서야 이루어집니다.
- 해결(Resolution)
해결은 자바 가상 머신(JVM)이 상수 풀에 있는 심볼릭 참조(symbolic reference)를 직접 참조(direct reference)로 변환하는 과정입니다. 자바는 프로그램 실행 시점에 필요한 클래스와 메서드를 동적으로 로딩하고 링크하는 다이내믹 링킹 방식을 사용합니다. 이로 인해 컴파일된 클래스 파일에는 다른 클래스나 메서드에 대한 참조가 실제 메모리 주소가 아닌 심볼릭 참조로 저장됩니다. 여기서 말하는 심볼릭 참조는 `CONSTANT_Class_info`, `CONSTANT_Fieldref_info`, `CONSTANT_Methodref_info` 등과 같은 참조를 의미합니다.
해결 과정은 주로 7가지 유형의 심볼릭 참조에 대해 수행되며, 이 7가지 유형은 클래스·인터페이스, 필드, 클래스 메서드, 인터페이스 메서드, 메서드 타입, 메서드 핸들, 호출 사이트 지정자입니다.
심볼릭 참조와 직접 참조를 쉽게 설명하자면:
- 심볼릭 참조(symbolic reference): 이름이나 경로를 사용하여 참조하는 방식입니다. 예를 들어, `MyClass.myMethod()`와 같이 클래스나 메서드의 이름을 통해 참조합니다. 이 경우 메모리 주소를 직접 사용하지 않고, 논리적인 식별자 이름을 통해 접근합니다.
- 직접 참조(direct reference): 실제 메모리 주소를 사용하여 참조하는 방식입니다. 심볼릭 참조를 해결한 뒤, 해당 이름에 대한 메모리 주소를 찾으면 이 참조는 직접 참조로 변환됩니다. 이후 프로그램은 메모리 주소를 통해 해당 클래스나 메서드, 데이터를 직접 접근할 수 있습니다.
좀 더 자세히 말해보면, 해결 단계에서는 클래스 A가 클래스 B의 메서드를 호출할 때 컴파일된 A 클래스 파일 내에 `B.someMethod()`라는 심볼릭 참조가 기록됩니다. 실행 시점에 클래스 로더는 이 심볼릭 참조를 찾아 메모리상의 실제 주소로 변환하고, 두 클래스 간의 연결을 설정합니다. 이 과정은 자바의 다이내믹 링킹 특성에 따라 실제 해당 참조가 사용되기 직전에 수행될 수 있습니다. 이는 필요할 때만 수행되는 지연된 과정으로, 프로그램의 효율성을 높입니다.
그렇다면 Java는 왜 다이내믹 링킹 방식을 쓸 수 밖에 없었을까요?
자바가 다이내믹 링킹을 선택하는 이유는 다음과 같습니다:
- 클래스의 실행 시 로딩
- 자바에서는 클래스가 실행 시점에 메모리에 로드됩니다. 컴파일 시점에는 클래스의 실제 메모리 주소를 알 수 없으므로, 심볼릭 참조를 직접 참조로 변환할 수 없습니다.
- 플랫폼 독립성
- 자바 바이트코드는 특정 플랫폼에 종속되지 않습니다. 실행 시점에 JVM이 해당 플랫폼에 맞게 바이트코드를 해석하고 실행하므로, 컴파일 시점에 메모리 주소를 고정할 수 없습니다.
- 유연한 업데이트와 유지보수
- 다이내믹 링킹을 통해 개별 클래스를 수정하거나 교체해도 전체 애플리케이션을 다시 컴파일하거나 배포할 필요가 없습니다.
- 메모리 효율성
- 필요한 클래스만 메모리에 로드하여 메모리 사용을 최적화할 수 있습니다.
- 동적 기능 지원
- 리플렉션(reflection)과 다형성(polymorphism)을 지원하여 실행 시점에 객체의 메서드나 필드를 동적으로 접근할 수 있습니다.
리플랙션(reflection)이란
리플렉션은 자바에서 실행 시점에 클래스, 메서드, 필드 등의 정보를 동적으로 조사하고 조작할 수 있게 해주는 기능입니다. 이를 통해 프로그램은 컴파일 시점에 알 수 없는 클래스나 메서드에도 접근할 수 있으며, 유연하고 확장성 있는 코드를 작성할 수 있습니다.
초기화 (Initialization)
초기화는 클래스 로딩의 마지막 단계입니다. 사용자 정의 클래스 로더를 이용해 앞서 소개한 단계 중 일부를 제어할 수 있지만, 초기화 대부분의 작업은 자바 가상 머신(JVM)이 통제합니다. 초기화 단계에 들어서면, JVM은 사용자 클래스에 작성된 자바 프로그램 코드를 실행하기 시작합니다. 이 단계에서 클래스 변수와 기타 자원이 개발자가 작성한 프로그램 코드에 따라 초기화됩니다.
좀 더 구체적으로 말하면, 초기화 단계는 클래스 생성자인 `<clinit>()` 메서드를 실행하는 과정입니다. `<clinit>()`는 자바 컴파일러가 자동으로 생성하는 메서드로, 개발자가 직접 자바 코드로 작성할 수는 없습니다.
초기화 단계에서는 `static` 필드가 실제 값으로 설정되고, `static` 초기화 블록이 실행됩니다. 예를 들어, `static final String STR = "ABC";`와 같이 선언된 `static` 필드들이 해당 값으로 초기화됩니다. 초기화는 클래스가 로드될 때 한 번만 수행되며, 이 과정이 끝나야 클래스가 완전히 준비된 상태가 됩니다.
메모리 영역 (Runtime Data Area)
런타임 데이터 영역은 JVM이 실행 중인 프로그램 데이터를 저장하고 관리하는 메모리 공간입니다. Java 프로그램이 실행되면서 필요한 데이터를 다루기 위해 메모리를 크게 메서드 영역(Method Area), 힙(Heap), 스택(Stack), PC 레지스터(Program Counter Register), 그리고 네이티브 메서드 스택(Native Method Stack)으로 나누어 관리합니다.

메서드 영역 (Method Area)
메서드 영역은 클래스 수준의 정보가 저장되는 영역입니다. 클래스의 이름, 부모 클래스 정보, 메서드와 변수 정보, 상수 풀 등이 이곳에 저장됩니다.
- JVM 내에서 메서드 영역은 하나만 존재하며 모든 스레드가 공유하는 영역입니다.
- Java 프로그램이 시작될 때 메서드 영역이 할당되고, 프로그램이 종료될 때까지 유지됩니다.
- 런타임 상수 풀(Run-Time Constant Pool)도 이 영역에 포함되어 있으며, 상수와 심볼릭 레퍼런스(symbolic reference)들이 저장되고, 실행 중에는 이 심볼릭 레퍼런스가 직접 참조로 해결됩니다.
힙 영역 (Heap Area)

힙은 동적으로 생성되는 객체와 배열이 저장되는 영역으로, 모든 스레드가 공유하는 공간입니다. `new` 키워드로 생성된 객체가 할당되며, 프로그램이 종료되거나 가비지 컬렉션이 발생할 때까지 유지됩니다. 힙 영역은 Young Generation과 Old Generation으로 나뉘어 관리되며, 메모리 효율을 높이기 위해 가비지 컬렉션이 효과적으로 작동하도록 설계되었습니다.
- Young Generation: 새로 생성된 객체가 처음으로 할당되는 영역으로, Eden 영역과 Survivor 영역(S0, S1)으로 구성되어 있습니다. 주로 Minor GC가 자주 발생하여 객체를 정리합니다.
- Old Generation: Young Generation에서 오래 살아남은 객체가 이동하는 영역입니다. Major GC가 발생하여 장기적으로 남아있는 객체를 정리합니다.
- Metaspace: Java 8 이후로, 클래스 메타데이터를 저장하는 PermGen을 대체한 영역입니다. 네이티브 메모리를 사용하므로 필요에 따라 자동 확장이 가능합니다.
스택 영역 (Stack Area)

스택 영역은 각 메서드 호출마다 생성되는 스택 프레임(Stack Frame)을 저장하는 공간입니다.
- 각 메서드를 호출할 때마다 로컬 변수, 연산 중간 결과, 호출 정보 등이 스택 프레임에 저장되며, 각 스레드마다 독립적인 스택을 가집니다.
- 스택은 LIFO(Last-In-First-Out) 방식으로 관리되며, 메서드 호출 시 프레임이 추가되고, 메서드가 종료되면 해당 프레임이 제거됩니다.
- 스택 오버플로우(StackOverflowError)는 메서드 호출이 계속되어 스택 영역이 부족할 때 발생할 수 있습니다.
PC Register

Program Counter(PC)는 각 스레드가 현재 실행 중인 명령어의 주소를 저장하는 작은 메모리 공간입니다.
- 스레드가 시작될 때 생성되며, 각 스레드마다 하나씩 존재합니다.
- 현재 명령어 주소를 기록하고, JVM이 어떤 명령어를 다음에 실행해야 할지 알려주는 역할을 합니다.
- 이를 통해 스레드는 독립적인 실행 흐름을 유지할 수 있으며, 다중 스레딩 환경에서 각 스레드의 진행 상태를 기록합니다.
네이티브 메서드 스택 (Native Method Stack)
네이티브 메서드 스택은 자바 외의 네이티브 코드(C, C++)로 작성된 메서드 호출을 처리하는 스택입니다.
- JVM은 운영체제의 기능을 활용할 때 네이티브 메서드를 사용할 수 있으며, 네이티브 메서드 스택을 통해 이 작업을 관리합니다.
- 각 스레드마다 개별적인 네이티브 메서드 스택을 가지며, 네이티브 메서드 호출 시 스택 프레임이 생성됩니다.
- 네이티브 메서드 호출이 끝나면 해당 스택 프레임이 제거됩니다.
실행 엔진 (Execution Engine)
실행 엔진은 JVM의 핵심 부분으로, 메모리에 로드된 바이트 코드를 실제로 기계어로 변환하고 실행하는 역할을 합니다.

실행 엔진 내부의 주요 구성 요소는 다음과 같습니다.
- 인터프리터 (Interpreter) : 바이트 코드를 해석하여 실행하는 역할을 수행합니다. 같은 메서드라도 여러번 호출될 때 매번 새로 수행해야 되기 때문에 이때 JIT 컴파일러를 사용합니다.
- JIT(Just In time) Compiler : 반복되는 코드를 발견하여 전체 바이트 코드를 컴파일하고 그것을 Native Code로 변경하여 사용합니다.
- 가비지 컬렉터 (Garbage Collector) : 더 이상 참조되지 않는 메모리 객체를 모아 제거하는 역할을 수행합니다.
네이티브 메서드 인터페이스 (Native Method Interface)
JVM은 네이티브 메서드 인터페이스를 통해 네이티브 라이브러리와 상호작용합니다. 예를 들어, `Thread` 클래스의 `currentThread()` 메서드는 C로 구현되어 있으며, 이러한 네이티브 메서드에는 `native` 키워드가 사용됩니다. 네이티브 메서드를 사용하는 주된 이유는 하드웨어와의 상호작용이나 성능 최적화 때문입니다.
다음은 가장 흔한 예제로 `Thread` 클래스의 `currentThread()` 메서드 예시입니다.
public static void main(String[] args) {
Thread.currentThread();
}
@IntrinsicCandidate
public static native Thread currentThread();
이 메서드는 Java가 아닌 C로 구현되어 있으며, `native` 키워드가 붙어 있습니다. 네이티브 메서드는 Java Native Interface(JNI)를 통해 호출됩니다. 또한, `native` 키워드를 사용하여 직접 네이티브 메서드를 구현할 수도 있으며, 관련 예제는 링크에서 확인할 수 있습니다.
Java Application 실행 과정
이제 클래스 `A`와 `B`를 예시로, Java 애플리케이션의 실행 과정을 설명하겠습니다.
class A {
private static final String STR = "ABC";
public static Long l = Long.valueOf(-1L);
public static int iii = 1;
public static C c = new C();
private final String a = "abc";
private int i;
private C cc = new C();
public static void main(...) {
A a = new A();
B b = new B();
}
}
class B extends A {
// ...
}
클래스 `A`와 `B`의 JVM 메모리 로딩 과정
Java 프로그램이 실행될 때, JVM은 처음으로 `Class A`를 참조하게 되면 이 클래스를 클래스 로더 시스템을 통해 메모리에 로드합니다.
- 로딩 (Loading)
`Class A`가 로드될 때, JVM은 클래스 파일을 찾고 메서드 영역에 `A` 클래스의 메타데이터(클래스 이름, 부모 클래스 정보, 메서드 시그니처 등)를 저장합니다. 이 과정에서 `A` 클래스의 `static` 필드들도 메서드 영역에 등록됩니다. - 링크 (Linking)
- 검증 (Verification): `A.class` 파일이 JVM 명세에 맞는지 검사합니다.
- 준비 (Preparation): `static` 필드인 `STR`, `l`, `iii`, `c`가 기본값으로 초기화됩니다.
- `STR`과 `l`은 `null`, `iii`는 `0`, `c`는 `null`로 설정됩니다.
- 해결 (Resolution): `Class A`에서 참조하는 클래스(`Long`, `C`)들이 실제 메모리 주소로 연결됩니다.
- 초기화 (Initialization)
- `Class A`의 `static` 필드들이 선언된 값으로 초기화됩니다.
- `STR`은 `"ABC"`로 설정되고,
- `l`은 `Long.valueOf(-1L)`로 초기화,
- `iii`는 `1`로,
- `c`는 `new C()`를 통해 `C` 클래스의 객체를 생성한 후, 그 참조값을 c에 할당합니다.
이렇게 `Class A`는 완전히 메모리에 로드되었으며 프로그램에서 사용할 준비가 된 상태가 됩니다. `Class B`도 필요 시 동일한 과정을 거쳐 메모리에 로드됩니다.
`main` 메서드가 실행될 때 JVM의 메모리 관리
`main` 메서드가 실행되면서 JVM은 메모리에 `main` 스레드를 생성하고 스택 영역에 `main` 메서드의 스택 프레임을 만듭니다. 이 스택 프레임에는 `main` 메서드에서 사용하는 로컬 변수들이 저장됩니다.
`A a = new A();` 실행 시
- `new A()`를 통해 힙 영역에 `A` 클래스의 인스턴스가 생성됩니다.
- 힙 메모리에는 A 인스턴스의 인스턴스 필드들이 할당됩니다:
- `a` 필드는 `"abc"`라는 문자열을 참조하며, 문자열 `"abc"`는 상수 풀에 저장됩니다.
- `i` 필드는 기본값 `0`으로 초기화됩니다.
- `cc` 필드는 `new C()`에 의해 생성된 `C` 객체의 참조를 가지게 됩니다. 이 `C` 객체 역시 힙에 할당됩니다.
- 스택 영역에 `main` 메서드의 로컬 변수 `a`가 할당되고, 이 변수는 힙에 있는 `A` 객체의 주소를 가리킵니다.
`B b = new B();` 실행 시
- `B b = new B();`가 실행되면서, 힙 영역에 `B` 클래스의 인스턴스가 생성됩니다. `B` 클래스는 `A` 클래스를 상속하므로, `B` 인스턴스에는 `A` 클래스의 필드도 포함됩니다.
- `a` 필드, `i` 필드, `cc` 필드를 포함하며, 각각의 필드는 기본값으로 초기화된 후 값이 설정됩니다.
- 스택 프레임에 b라는 로컬 변수가 생성되어, 힙에 있는 B 객체를 참조하게 됩니다.
아토믹성(Atomicity)이란?
아토믹성(Atomicity)이라는 말은 작업이 더 이상 쪼갤 수 없는 하나의 단위로 실행된다는 의미인데요.
어떤 작업이 아토믹하다고 하면, 그 작업이 중간에 다른 작업에 방해받지 않고 한 번에 완전히 실행된다는 뜻입니다.
초기화 과정에서 아토믹 보장이 이루어지는 이유
자바의 클래스 초기화는 JVM이 스레드 안전성을 보장합니다. 초기화 과정에서 `static` 필드들이 설정될 때, 다른 스레드가 중간에 값을 읽거나 개입할 수 없도록 동기화가 이루어집니다.
- `static final` 필드나 클래스 초기화 시점의 값은 컴파일 타임에 결정되거나, 초기화 단계에서 한 번 설정된 후에는 변경되지 않아요.
- `static` 필드는 클래스 로딩 시점에 한 번만 초기화되며, JVM은 이 초기화를 동기화하여 단일 스레드가 초기화 작업을 수행하도록 보장합니다. 이 덕분에 다른 스레드가 초기화 중간에 값을 읽거나 개입할 수 없습니다.
- 이로 인해 `static final` 필드는 아토믹하게 초기화가 보장되고, 초기화 완료 후 다른 스레드가 접근하더라도 일관된 값을 읽을 수 있습니다.
참고
- 책 JVM 밑바닥까지 파헤치기
- 유튜브 자바(Java) 메모리 구조 소개 - https://www.youtube.com/watch?v=zta7kVTVkuk
- 인프런 강의 더 자바, 코드를 조작하는 다양한 방법 - https://inf.run/DBUHD
- 패스트캠퍼스 강의 The RED : 성능의 神: 궁극의 성능 튜닝과 트러블슈팅 by 이상민 - https://fastcampus.co.kr/dev_red_lsm
'🎨 Language' 카테고리의 다른 글
| 가비지 컬렉터 G1 GC 🗑️ (3) | 2024.11.17 |
|---|---|
| HotSpot VM과 JIT 컴파일러🔥 (1) | 2024.11.16 |