


이번 포스팅에서는 운영체제의 핵심 개념인 프로세스와 스레드에 대해 자세히 알아보겠습니다.
프로세스
프로세스(process)는 한마디로 프로그램이 실행 중인 상태, 즉 실행 중인 프로그램의 인스턴스를 의미합니다. 우리가 컴퓨터에서 어떤 소프트웨어를 실행하면, 그 프로그램 파일이 디스크에서 메모리로 로드되고, 운영체제로부터 CPU 자원을 할당받아 명령을 하나씩 수행하게 되는데요. 이 과정이 바로 프로세스입니다. 운영체제에서 프로세스는 자원을 할당받는 최소 작업 단위로 정의되며, 각 프로세스는 자신만의 독립된 메모리 공간을 갖습니다.
이 독립성 덕분에 프로세스들은 서로 간섭하지 않고 안정적으로 실행될 수 있는데요. 예를 들어 엑셀과 동시에 카카오톡을 실행한다고 해보면, 두 프로세스는 각각 독립적으로 동작합니다. 엑셀이 갑자기 오류로 인해 종료되더라도 카카오톡은 영향을 받지 않는 것도 이 때문입니다. 하지만 이런 독립성 때문에 프로세스 간 전환(컨텍스트 스위치)이 발생할 때는 메모리와 CPU 자원을 많이 소모한다는 단점도 있습니다.
스레드
스레드(thread)는 프로세스 안에서 실행되는 가장 작은 단위입니다. 프로세스가 운영체제로부터 할당받은 자원을 활용해서 실제 작업을 수행하는 주체가 바로 스레드인데요. 하나의 프로세스는 반드시 최소 하나 이상의 스레드를 가지고 있고, 이 스레드들이 자원을 공유하면서 동시에 여러 작업을 처리할 수 있습니다. 이런 특징 덕분에 스레드는 경량 프로세스(Lightweight Process)라고도 불립니다. 프로세스에 비해 생성과 전환 비용이 적고, 자원을 효율적으로 사용할 수 있기 때문입니다.
웹 브라우저를 생각했을 때 여러 탭을 동시에 열어놓으면 각 탭이 독립적으로 동작하는데, 이게 가능한 이유는 각 탭이 하나의 스레드로 실행되면서 프로세스의 자원을 공유하기 때문입니다. 스레드는 프로세스의 메모리 공간을 함께 쓰기 때문에 데이터 교환이 빠르지만, 그만큼 동기화 문제가 발생할 수 있습니다.
프로세스와 스레드의 주요 차이점
프로세스와 스레드는 실행 단위라는 점에서 공통점이 있지만, 메모리와 자원의 사용 방식에서 중요한 차이가 있습니다. 이런 차이점들을 종합적으로 비교해 보면 다음과 같습니다.
- 자원 공유 방식
- 프로세스 : 각 프로세스는 완전히 독립된 메모리 공간(Code, Data, Stack, Heap)을 가집니다. 다른 프로세스의 자원에 직접 접근할 수 없으며, 프로세스 간 통신(IPC)을 통해서만 데이터를 교환할 수 있습니다.
- 스레드 : 같은 프로세스 내의 스레드들은 Code, Data, Heap 영역을 공유합니다. 각 스레드는 독립된 Stack만 가집니다. 공유 메모리를 통해 빠르게 데이터를 교환할 수 있지만, 동기화 문제가 발생할 수 있습니다.
- 컨텍스트 스위칭 비용
- 프로세스 전환 : 프로세스는 독립적인 메모리 구조를 사용하므로 전환 시 운영체제가 전체 메모리 상태를 교체해야 합니다. 이로 인해 CPU 캐시 초기화와 PCB(Process Control Block) 복원이 필요하며, 전환 비용(오버헤드)이 큽니다.
- 스레드 전환 : 같은 프로세스 내에서 이루어지므로 메모리(Code, Data, Heap)를 교체할 필요가 없습니다. 독립된 Stack과 레지스터만 교체하면 되기 때문에 상대적으로 오버헤드가 적습니다.
- 생성 및 종료 비용
- 프로세스 : 생성 시 독립적인 메모리 공간을 할당하고 초기화해야 하므로 비용이 큽니다. 종료 시에도 모든 자원을 회수하는 작업이 필요합니다.
- 스레드 : 기존 프로세스의 자원을 공유하므로 생성 비용이 적습니다. 새로운 스택과 레지스터 세트만 할당하면 됩니다. 종료 시에도 스택만 정리하면 되므로 비용이 적습니다.
- 안정성과 독립성
- 프로세스 : 하나의 프로세스가 충돌해도 다른 프로세스에 영향을 주지 않습니다. 안전한 독립성을 가지므로 안정성이 높습니다.
- 스레드 : 같은 프로세스 내의 한 스레드가 충돌하면 전체 프로세스에 영향을 미칠 수 있습니다. 자원을 공유하므로 독립성이 낮지만, 협력이 용이합니다.
이러한 차이점들을 아래 표로 정리해볼 수 있습니다.
| 특성 | 프로세스 | 스레드 |
| 정의 | 실행 중인 프로그램 | 프로세스 내의 실행 흐름 |
| 메모리 공간 | 독립적인 메모리 공간 | 프로세스의 메모리 공간 공유 |
| 자원 공유 | 다른 프로세스와 자원 공유 안 함 | 같은 프로세스 내 스레드와 자원 공유 |
| 통신 방식 | IPC 메커니즘 필요 | 공유 메모리를 통한 직접 통신 |
| 생성 비용 | 높음 | 낮음 |
| 컨텍스트 스위칭 비용 | 높음 | 낮음 |
| 안정성 | 한 프로세스 오류가 다른 프로세스에 영향 없음 | 한 스레드 오류가 전체 프로세스에 영향 |
| 병렬 처리 | 멀티 프로세싱 | 멀티스레딩 |
| 예시 | 웹 브라우저, 워드 프로세서 | 웹 페이지 렌더링, 데이터 저장 스레드 |
프로세스의 메모리 구조
프로세스가 실행되려면 운영체제로부터 메모리 공간을 할당받아야 합니다. 이 메모리 공간은 Code, Data, Stack, Heap이라는 네 가지 주요 영역으로 나뉩니다.
- Code (코드 영역)
코드 영역은 프로그램의 실행 가능한 명령어들이 저장되는 곳인데요. 우리가 작성한 함수나 로직이 여기에 포함됩니다. 예를 들어, C언어로printf("Hello, World!");를 작성하면, 이 코드가 컴파일러에 의해 기계어로 번역돼서 코드 영역에 저장됩니다. 이 영역은 일반적으로 읽기 전용(ROM)으로 설정되어 있어서 실행 중에 수정되지 않습니다. 프로그램의 무결성을 유지하고, 같은 코드를 여러 프로세스가 공유할 수 있게 해서 메모리를 절약하기 위함입니다. - Data (데이터 영역)
데이터 영역은 전역 변수, 정적 변수, 상수처럼 프로그램이 실행되는 동안 유지되어야 하는 데이터를 저장합니다. 이 영역은 프로세스가 시작될 때 할당되고, 종료될 때 해제됩니다. 읽기/쓰기가 가능하지만, 초기화 여부에 따라 세부적으로 나뉩니다. 초기화된 전역 변수(예:int globalVar = 10;)는 데이터 영역에, 초기화되지 않은 변수(예:int globalVar;)는 BSS(Block Started by Symbol)라는 특수 영역에 할당됩니다. BSS 영역의 변수들은 실행 파일에 실제 값이 저장되지 않아 디스크 공간을 절약하며, 로드 시 자동으로 0으로 초기화되는 특징이 있습니다. - Stack (스택 영역)
스택은 함수 호출과 관련된 임시 데이터를 저장하는 공간으로, 지역 변수, 함수의 매개변수, 리턴 주소 등이 쌓이게 됩니다. LIFO(Last In, First Out) 구조로 동작해서, 가장 최근에 호출된 함수의 데이터가 먼저 제거됩니다. 이 구조 덕분에 함수가 끝나면 자동으로 메모리가 해제되는데요. 스택은 크기가 제한적이어서, 너무 깊은 재귀 호출이 발생하는 등 많은 데이터를 쌓으면 스택 오버플로우(Stack Overflow)가 발생할 수 있습니다. - Heap (힙 영역)
힙은 개발자가 필요에 따라 동적으로 메모리를 할당하는 공간입니다. 예를 들어, 프로그램 실행 중 사용자가 입력한 데이터의 크기에 따라 메모리를 할당해야 할 때,malloc()이나new를 사용해 힙 영역에서 메모리를 확보할 수 있습니다. 사용 후에는 직접 해제(free()나delete)해야 하며, 관리를 잘못하면 메모리 누수(Memory Leak)가 생길 수 있습니다. 또한 여러 스레드가 동시에 접근할 수 있기 때문에 동기화 문제도 발생할 수 있습니다.
프로세스 상태
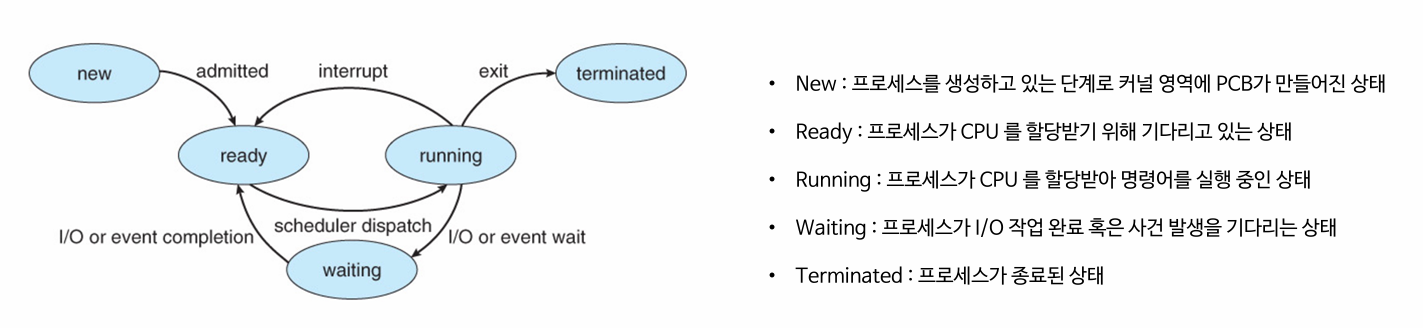
프로세스는 실행되는 동안 다음과 같은 5가지 상태를 거치며, 이 상태들은 스케줄러의 역할과 컨텍스트 스위칭에 의해 결정됩니다. 주요 상태를 간단히 설명하자면 다음과 같습니다.
New(생성)
- 프로세스가 처음 만들어지는 단계입니다. 사용자가 프로그램을 실행하면, 운영체제는 디스크에서 프로그램 파일을 메모리로 로드하고, 해당 프로세스에 고유한 PCB(Process Control Block)를 생성합니다. 이 상태에서는 아직 실행 준비가 완료되지 않았으며, 메모리 할당과 초기 설정이 끝나야 다음 단계로 넘어갈 수 있습니다.
Ready(준비)
- 프로세스가 CPU를 할당받을 준비가 된 상태로, 준비 큐(Ready Queue)라는 대기열에서 스케줄러의 선택을 기다립니다. 이 상태의 프로세스는 모든 자원을 갖췄지만, CPU가 다른 프로세스를 실행 중이라 대기 중인 상황입니다.
Running(실행)
- 프로세스가 CPU를 할당받아 명령어를 실행하는 상태입니다. 단일 코어에서는 한 번에 하나의 프로세스만 Running 상태일 수 있고 멀티코어 환경에서는 코어 수만큼 동시에 실행될 수 있습니다.
Blocked(대기)
- 프로세스가 CPU를 사용하지 않고, I/O 작업이나 특정 이벤트(예: 사용자 입력, 타이머)를 기다리는 상태입니다. 이 상태에서는 CPU를 다른 프로세스에 양보해 시스템 효율성을 높입니다.
Exit(종료)
- 프로세스가 모든 작업을 마치고 종료된 상태입니다. 운영체제는 할당했던 메모리와 자원을 회수하고, PCB를 삭제합니다. 이 상태에 도달하면 프로세스는 더 이상 존재하지 않습니다.
프로세스 제어 블록(PCB)
운영체제는 수많은 프로세스를 동시에 관리해야 하는데, 이를 위해 PCB(Process Control Block)라는 자료구조를 사용합니다. PCB는 각 프로세스의 '신분증' 같은 존재로, 운영체제가 프로세스를 추적하고 제어하는 데 필요한 모든 정보를 담고 있습니다. 만약 PCB가 없다면 운영체제는 프로세스가 어디 있는지, 뭘 하고 있는지 알 수 없게 됩니다.
PCB에 담긴 정보
PCB에는 프로세스를 관리하는 데 필수적인 데이터가 저장되는데, 주요 내용은 다음과 같습니다.
- 프로세스 ID(PID): 프로세스를 식별하는 고유 번호입니다. 작업 관리자에서 PID 열을 보면 각 프로세스가 숫자로 식별되는 것을 볼 수 있습니다.
- 프로세스 상태 : 현재 New, Ready, Running, Blocked, Exit 중 어떤 상태인지 나타냅니다.
- CPU 레지스터 값 : 프로세스가 중단될 때 현재 CPU의 상태(레지스터 값)를 저장합니다. 나중에 다시 실행할 때 이 값을 복원해서 중단된 지점부터 이어갈 수 있습니다.
- Program Counter (PC) : 다음에 실행할 명령어의 메모리 주소를 가리킵니다. 만약 코드 실행이 중단되면 PC에 다음 줄의 주소를 저장해 놓습니다.
- 메모리 정보 : Code, Data, Stack, Heap 영역의 위치와 크기 등 메모리 할당 정보를 포함합니다. 운영체제가 프로세스의 메모리를 관리하는 데 필요합니다.
- 스케줄링 정보 : 프로세스의 우선순위나 실행 순서를 결정하는 데이터입니다. 스케줄러가 이 정보를 보고 CPU를 누구에게 줄지 판단합니다.
프로세스 간 통신(IPC)
프로세스는 독립된 메모리 공간을 가지기 때문에 서로의 데이터에 직접 접근할 수 없지만 협력이 필요한 경우가 많습니다. 예를 들어, 웹 서버가 데이터베이스에서 데이터를 가져와야 한다면 이때 운영체제가 제공하는 IPC(Inter-Process Communication) 매커니즘이 필요합니다. IPC는 프로세스 간 데이터를 주고받게 해주는 다리 역할을 합니다. 대표적인 방법은 다음과 같습니다.
파이프(Pipie)
가장 단순한 형태의 IPC로, 단방향 통신 채널을 제공합니다. 주로 부모-자식 프로세스 간 통신에 사용됩니다.
- 익명 파이프 (Anonymous Pipe) : 관련된 프로세스 간에만 사용 가능하며, 파일 시스템에 이름이 없습니다.
- 명명된 파이프 (Named Pipe) : 이름이 있어 관련 없는 프로세스 간에도 통신이 가능합니다.
리눅스 쉘에서 ls | grep "txt"와 같은 명령을 실행할 때 파이프(|)가 두 프로세스 간 통신을 가능하게 합니다. 첫 번째 프로세스(ls)의 출력이 두 번째
프로세스(grep)의 입력으로 직접 전달됩니다.
메시지 큐(Message Queue)
구조화된 메시지를 교환할 수 있는 통신 방식으로, 비동기적 통신이 가능합니다. 메시지는 큐에 저장되어 순서대로 처리됩니다.
- 메시지마다 우선순위를 부여할 수 있어 중요한 메시지를 먼저 처리할 수 있습니다.
- 여러 프로세스가 동시에 같은 큐를 사용할 수 있습니다.
은행 시스템을 예로 들면, 고객 처리 애플리케이션이 트랜잭션 메시지를 큐에 넣고, 백엔드 처리 프로세스가 이 메시지를 순차적으로 꺼내 처리하는 방식으로 동작할 수 있습니다.
공유 메모리(Shared Memory)
여러 프로세스가 동일한 메모리 영역을 공유하는 방식으로 가장 빠른 IPC 방법입니다.
- 데이터 복사 없이 직접 접근하기 때문에 속도가 빠르다는 장점이 있습니다.
- 동기화 문제를 해결하기 위해 세마포어나 뮤텍스와 함께 사용합니다.
비디오 편집 소프트웨어에서 재생 프로세스와 효과 적용 프로세스가 동일한 비디오 프레임 데이터를 공유 메모리를 통해 접근하면, 대용량 데이터를 복사하지 않고도 효율적으로 작업할 수 있습니다.
세마포어(Semaphore)
공유 자원에 대한 접근을 제어하는 신호 메커니즘으로, 주로 동기화에 사용됩니다.
- 여러 프로세스가 공유 자원에 동시 접근하는 것을 방지합니다.
- 이진 세마포어(Binary Semaphore)와 카운팅 세마포어(Counting Semaphore)로 구분됩니다.
프린터 스풀러 시스템에서 여러 프로세스가 동시에 프린터에 출력 요청을 보내더라도, 세마포어를 통해 한 번에 하나의 프로세스만 프린터 자원에 접근하도록 제어합니다.
소켓(Socket)
네트워크 인터페이스를 통해 통신하는 방식으로, 로컬 및 원격 통신에 모두 사용 가능합니다.
- 다른 컴퓨터의 프로세스와도 통신이 가능합니다.
- TCP/UDP 프로토콜을 모두 지원합니다.
웹 브라우저와 웹 서버는 소켓을 통해 통신하며, 브라우저는 HTTP 요청을 서버에 보내고 서버는 응답을 반환합니다. 서로 다른 컴퓨터에서 실행되는 프로세스 간 통신의 대표적인 예시입니다.
메모리 맵 파일(Memory-Mapped File)
파일을 메모리에 맵핑하여 프로세스 간 공유하는 방식입니다.
- 파일 I/O와 메모리 접근을 결합한 방식입니다.
- 대용량 파일 처리에 효율적입니다.
데이터베이스 시스템에서는 메모리 맵 파일을 사용해 대용량 데이터 파일을 여러 프로세스가 빠르게 접근하고 수정할 수 있게 합니다.
스레드의 구조
스레드는 프로세스 안에서 동작하지만, 자신만의 독립적인 부분과 공유하는 부분이 명확히 나뉘어 있습니다. 프로세스가 할당받은 메모리 공간 중 Code, Data, Heap 영역은 스레드들이 함께 사용하고, Stack 영역만 각 스레드마다 따로 갖습니다. 이 구조를 자세히 살펴보겠습니다.
스택 영역 (Stack)
각 스레드는 독립된 스택을 가지고 있습니다. 이 공간은 함수 호출과 관련된 임시 데이터를 저장하는 곳인데요. 지역 변수, 함수의 매개변수, 리턴 주소 등이 여기에 쌓입니다. 스택은 LIFO(Last In, First Out) 구조로 동작해서, 가장 최근에 호출된 함수의 데이터가 먼저 제거됩니다. 예를 들어, 웹 브라우저에서 한 탭에서는 이미지를 로딩하는 함수를, 다른 탭에서는 텍스트를 처리하는 함수를 별도로 실행할 수 있는데, 이는 각 스레드가 독립된 스택을 가지고 있기 때문입니다.
공유 영역 (Code, Data, Heap)
스레드는 프로세스의 Code 영역에서 실행할 명령어를 가져오고, Data 영역에서 전역 변수나 정적 변수를 참조하며, Heap 영역에서 동적 메모리를 할당받습니다. 예를 들어, 워드프로세서에서 여러 스레드가 동시에 문서 편집, 자동 저장, 맞춤법 검사를 담당할 때, 모두 같은 문서 데이터(Heap에 저장)에 접근합니다.
레지스터 (Registers)
스레드가 CPU를 사용할 때는 현재 실행 상태를 저장하기 위해 CPU의 레지스터를 활용하는데요. 여기에는 프로그램 카운터(PC)나 스택 포인터(SP) 같은 값이 포함됩니다. 스레드가 다른 스레드로 전환될 때 이 레지스터 값이 저장되고, 다시 돌아올 때 복원돼서 중단된 지점부터 이어갈 수 있습니다.
스레드 고유 데이터 (Thread-Specific Data)
스레드마다 자신만의 데이터를 가질 수도 있는데요. 이건 스레드 로컬 저장소(Thread Local Storage, TLS)에 저장됩니다. 웹 서버에서 각 클라이언트 요청을 처리하는 스레드가 자신만의 세션 정보를 독립적으로 관리하는 경우가 이에 해당합니다.
스레드 상태
스레드도 프로세스와 유사한 생명 주기를 가지지만, 프로세스 내부에서 동작한다는 특성이 반영됩니다. 대부분의 운영체제에서 스레드 상태는 프로세스 상태와 유사하게 관리되지만, 프로그래밍 언어나 라이브러리에 따라 추가적인 상태가 정의되기도 합니다. 자바 스레드 모델을 기준으로 스레드 상태는 다음과 같이 정의됩니다.
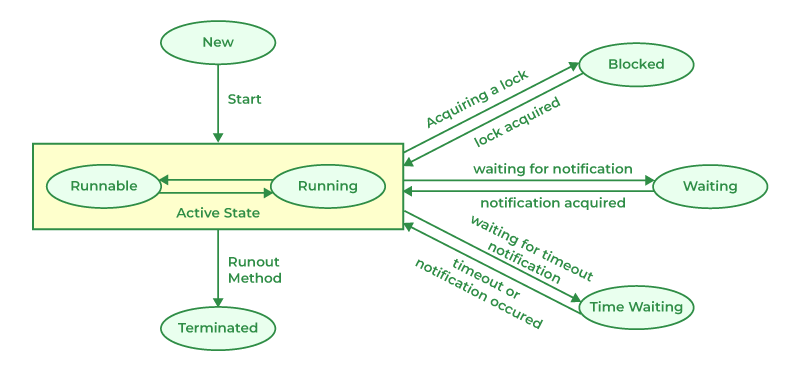
New (생성)
스레드 객체가 생성되었지만 아직 start() 메소드가 호출되지 않은 상태입니다. 이 상태에서는 스레드가 아직 실행 대상으로 등록되지 않았습니다.
Runnable (실행 가능)
start() 메소드가 호출되어 실행 대기 중인 상태로, CPU를 할당받으면 바로 실행될 수 있습니다. 운영체제 수준에서는 Ready와 Running 상태를 모두 포함합니다.
Blocked/Waiting (차단/대기)
스레드가 일시적으로 실행을 멈추고 특정 조건이나 이벤트를 기다리는 상태입니다.
- Blocked : 모니터 락(monitor lock) 획득을 기다리는 상태
- Waiting :
wait(),join()등의 메소드 호출로 무기한 대기 중인 상태 - Timed Waiting :
sleep(1000),wait(1000)등으로 특정 시간 동안만 대기하는 상태
Terminated (종료)
스레드가 실행을 완료하고 종료된 상태입니다. 런타임 예외가 발생해도 이 상태로 전환됩니다.
스레드 제어 블록(TCB)
운영체제가 스레드를 관리하려면 각 스레드의 정보를 추적할 방법이 필요합니다. 이때 사용하는 게 바로 스레드 제어 블록(Thread Control Block, TCB)입니다. TCB는 프로세스의 PCB와 유사하지만 스레드에 특화된 정보를 담고 있습니다.
TCB에 담긴 정보
- 스레드 ID(TID): 스레드를 식별하는 고유 번호입니다.
- 스레드 상태 : 스레드가 지금 어떤 상태인지 나타냅니다.
- CPU 레지스터 값 : 스레드가 실행 중에 중단되면 현재 레지스터 상태를 저장합니다. 나중에 다시 실행할 때 이 값을 복원해서 끊김 없이 이어갈 수 있습니다.
- 스택 포인터 : 스레드의 스택이 메모리 어디에 있는지 가리킵니다. 독립된 스택을 관리하려면 이 정보가 반드시 필요합니다.
- 우선순위 : 스레드마다 실행 순서나 중요도를 결정하는 값입니다. 운영체제가 여러 스레드 중 누구에게 CPU를 먼저 줄지 판단할 때 참고합니다.
- PCB 포인터 : 스레드가 속한 프로세스의 PCB를 가리키는 포인터입니다. 스레드는 프로세스의 종속되어 있으므로 이 연결 정보가 필요합니다.
TCB가 PCB보다 가벼운 이유는 Code, Data, Heap 영역 정보는 프로세스의 PCB에 이미 저장되어 있어 TCB에는 이런 공유 정보가 중복해서 저장되지 않기 때문입니다.
컨텍스트 스위칭(Context Switch)
컨텍스트 스위칭(Context Switching)은 현재 실행 중인 프로세스나 스레드에서 다른 프로세스나 스레드로 CPU 제어권을 넘기는 과정을 말합니다. 이 과정에서 현재 실행 중인 프로세스나 스레드의 상태가 저장되고, 다음에 실행할 프로세스나 스레드의 상태가 복원됩니다.
컨텍스트 스위칭의 발생 원인
컨텍스트 스위칭은 다음과 같은 여러 상황에서 발생합니다:
- 시간 할당량 만료: 라운드 로빈 같은 스케줄링에서 한 프로세스/스레드의 시간이 다 되었을 때
- 우선순위: 더 높은 우선순위의 프로세스/스레드가 실행 준비되었을 때
- I/O 요청: 프로세스/스레드가 입출력 작업을 요청하고 완료를 기다릴 때
- 동기화 이벤트: 세마포어, 뮤텍스 등에서 블록될 때
- 명시적 양보:
yield()같은 시스템 콜로 자발적으로 CPU를 양보할 때
컨텍스트 스위칭의 과정
컨텍스트 스위칭은 일반적으로 다음 단계로 진행됩니다.
- 현재 실행 중인 프로세스/스레드의 상태 저장 (PCB/TCB에 컨텍스트 저장)
- 새로운 프로세스/스레드 선택 (스케줄러가 수행)
- 새 프로세스/스레드의 컨텍스트 복원
- 새 프로세스/스레드에게 CPU 제어권 이전
예를 들어, 워드 프로세서에서 문서 편집 중에 음악 재생 프로그램이 더 높은 우선순위를 가지게 되면, 운영체제는 워드 프로세서의 상태를 PCB에 저장하고 음악 프로그램의 상태를 복원하여 CPU 제어권을 넘깁니다.
프로세스 vs 스레드 컨텍스트 스위칭
프로세스와 스레드 간의 컨텍스트 스위칭은 비용 측면에서 큰 차이가 있습니다. 프로세스 컨텍스트 스위칭은 전체 메모리 주소 공간을 전환해야 하므로 비용이 큽니다. MMU 재구성, TLB 플러시, 캐시 적중률 저하, CPU 파이프라인 플러시 등이 필요하기 때문인데요. 마치 한 사람이 완전히 다른 일터로 이동하면서 모든 업무 자료와 환경을 바꾸는 것과 같습니다.
반면 스레드 컨텍스트 스위칭은 같은 메모리 주소 공간 내에서 발생하므로 MMU 재구성이 필요 없고, 스택과 레지스터 정보만 교체하면 됩니다. 공유 코드와 데이터로 인해 캐시 적중률도 유지될 수 있어 자원 비용이 적고 빠르게 처리됩니다. 같은 회사 내에서 한 업무에서 다른 업무로 전환하는 것과 비슷하게, 기본 환경은 그대로 유지하면서 작업 내용만 바뀌는 것입니다.
컨텍스트 스위칭 비용의 영향
빈번한 컨텍스트 스위칭은 시스템 성능에 부정적인 영향을 미칠 수 있습니다.
- CPU 시간 낭비 (실제 작업 대신 스위칭에 사용)
- 캐시 효율성 저하
- 메모리 부담 증가
- 예측 불가능한 지연시간 발생
따라서 효율적인 시스템 설계에서는 필요한 병렬성을 유지하면서도 과도한 컨텍스트 스위칭을 줄이는 것이 중요합니다. 이는 적절한 스레드 풀 크기 설정, 작업 배치 처리, 비동기 I/O 사용 등의 기법을 통해 달성할 수 있습니다.
스케줄러 유형
운영체제는 CPU와 시스템 자원을 효율적으로 관리하기 위해 여러 종류의 스케줄러를 사용합니다. 각 스케줄러는 서로 다른 시간 척도와 목적으로 작동합니다.
장기 스케줄러(Long-Term Scheduler)
작업 스케줄러(Job Scheduler)라고도 불리며, 어떤 프로세스를 시스템에 들여보낼지 결정합니다. 디스크에 대기 중인 작업들 중 어떤 것을 메모리로 가져와 실행할지 결정하며, 시스템의 전체 프로세스 부하(Degree of Multiprogramming)를 제어합니다. 현대의 시분할(Time-Sharing) 시스템에서는 장기 스케줄러의 역할이 축소되어, 대부분의 운영체제는 사용자가 프로그램을 실행하면 바로 프로세스를 생성하는 방식을 채택하고 있습니다.
중기 스케줄러(Medium-Term Scheduler)
시스템의 부하를 조절하기 위해 프로세스를 메모리에서 임시로 제거하는 역할을 합니다. 메모리에 로드된 프로세스를 일시적으로 디스크로 스왑아웃(swap out)하거나 다시 메모리로 스왑인(swap in)하는 작업을 수행합니다. 메모리 관리와 다중 프로그래밍 정도를 조절하는 중요한 역할을 하며, 메모리가 부족하거나 너무 많은 프로세스가 실행 중일 때 우선순위가 낮거나 장시간 I/O를 기다리는 프로세스를 메모리에서 제거합니다.
단기 스케줄러(Short-Term Scheduler)
CPU 스케줄러(CPU Scheduler)라고도 불리며, CPU를 어떤 프로세스에게 할당할지 결정합니다. Ready 상태의 프로세스 중 어떤 것이 다음에 CPU를 사용할지 결정하며, 매우 자주 작동하기 때문에 시스템의 응답성과 성능에 직접적인 영향을 미칩니다. 컨텍스트 스위칭을 직접 제어하고 다양한 스케줄링 알고리즘에 따라 작동합니다.
CPU/IO 바운드 프로세스
프로세스는 CPU 사용 패턴에 따라 크게 두 가지로 분류할 수 있습니다.
CPU 바운드 프로세스(CPU-bound process): CPU 버스트가 길고 I/O 버스트가 짧은 프로세스로, 주로 계산 작업이 많은 프로그램이 해당됩니다. 과학 계산, 그래픽 렌더링, 암호화, 데이터 분석, 3D 모델링 같은 작업이 대표적인 예시입니다. CPU 바운드 프로세스는 긴 시간 할당량이 효율적이며, 우선순위를 낮게 설정할 수 있습니다.
I/O 바운드 프로세스(I/O-bound process): I/O 버스트가 길고 CPU 버스트가 짧은 프로세스로, 입출력 작업이 많은 프로그램이 해당됩니다. 데이터베이스 서버, 파일 서버, 웹 서버, 대화형 응용 프로그램, 네트워크 서비스 등이 대표적인 예시입니다. I/O 바운드 프로세스는 짧은 시간 할당량과 빠른 응답 시간이 중요하며, 우선순위를 높게 설정하는 것이 유리합니다.
Burst
프로세스가 실행되는 동안 CPU 연산이 집중되는 시기(CPU 버스트)와 입출력 작업이 이루어지는 시기(I/O 버스트)가 번갈아 나타납니다.
CPU 버스트(CPU burst): 프로세스가 CPU를 활발하게 사용하여 연산을 수행하는 시간입니다. 복잡한 계산이나 데이터 처리가 이루어지는 구간이 해당되며, 연속적인 명령어 실행과 높은 CPU 사용률을 보입니다. 버스트 길이는 프로세스마다 다양하며, 주로 지수 분포(exponential distribution)를 따르는 경향이 있습니다.
I/O 버스트(I/O burst): 프로세스가 입출력 작업을 기다리는 시간입니다. 디스크에서 파일을 읽거나 네트워크 패킷을 기다리는 동안의 시간이 이에 해당하며, CPU 사용 없이 외부 장치의 응답을 기다립니다. 버스트 길이는 장치 종류, 데이터 크기, 시스템 부하에 따라 크게 변동합니다.
버스트 패턴을 분석하면 프로세스의 특성을 파악하고 적절한 스케줄링 결정을 내릴 수 있습니다. 예를 들어, 짧은 CPU 버스트를 가진 프로세스에 우선순위를 부여하거나, I/O 바운드 프로세스의 응답 시간을 개선하는 등 효율적인 자원 관리가 가능합니다.
스레드 스케줄링
운영체제는 여러 스레드를 효율적으로 관리하기 위해 스레드 스케줄링 알고리즘을 사용하는데요. 스케줄링은 한정된 CPU 자원을 어떤 스레드에게 언제, 얼마나 할당할지 결정하는 과정을 의미합니다.
주요 스케줄링 알고리즘
선입선출 (FIFO) / FCFS (First-Come-First-Served)
가장 단순한 스케줄링 방식으로, 준비 큐에 도착한 순서대로 CPU를 할당합니다. 은행에서 번호표를 뽑아 순서대로 창구에 가는 것과 유사합니다. 공정하게 처리되지만, 실행 시간이 긴 스레드 하나가 CPU를 오래 점유하면 다른 스레드들이 모두 기다려야 하는 단점이 있습니다.
라운드 로빈 (Round Robin)
각 스레드에 동일한 시간 할당량(time quantum)을 부여하고, 시간이 만료되면 다음 스레드에게 CPU를 넘깁니다. 놀이공원에서 각 방문객이 정해진 시간 동안만 어트랙션을 이용할 수 있게 하는 것과 비슷한 원리입니다. 모든 스레드가 공평하게 CPU를 사용할 수 있지만, 문맥 교환(context switching) 비용이 증가하는 단점이 있습니다.
우선순위 기반 스케줄링 (Priority-based Scheduling)
각 스레드에 우선순위를 부여하고, 높은 우선순위의 스레드에게 CPU를 먼저 할당합니다. 병원 응급실에서 위급한 환자를 먼저 치료하는 것과 유사합니다. 중요한 작업을 빠르게 처리할 수 있지만, 우선순위가 낮은 스레드는 계속 뒤로 밀려 실행되지 못할 수 있으며 이것을 기아 현상(starvation)이라 합니다.
다단계 큐(Multilevel Queue)
스레드를 여러 종류의 큐로 분류하고, 각 큐마다 다른 스케줄링 알고리즘을 적용합니다. 예를 들어, 포그라운드 프로세스(사용자 상호작용)는 라운드 로빈, 백그라운드 프로세스는 FCFS 방식으로 처리할 수 있습니다. 다양한 작업 특성에 맞는 스케줄링이 가능하지만, 구현이 복잡하고 큐 간 자원 분배가 어렵다는 단점이 있습니다.
다단계 피드백 큐(Multilevel Feedback Queue)
다단계 큐를 확장한 형태로, 스레드의 동작 패턴에 따라 다른 큐로 이동할 수 있는 방식입니다. CPU 집약적인 스레드는 점점 낮은 우선순위 큐로 이동하고, I/O 집약적인 스레드는 높은 우선순위 큐에 유지됩니다. 다양한 작업 특성에 동적으로 대응할 수 있지만, 가장 복잡한 구현을 필요로 합니다.
스케줄링 목표와 성능 지표
CPU 스케줄링의 주요 목표와 이를 측정하는 성능 지표는 다음과 같습니다.
- CPU 이용률(CPU Utilization): CPU가 얼마나 바쁘게 일하는지를 나타내는 지표로, 높을수록 좋습니다.
- 처리량(Throughput): 단위 시간당 완료되는 프로세스의 수로, 높을수록 좋습니다.
- 반환 시간(Turnaround Time): 프로세스가 시작부터 종료까지 걸리는 총 시간으로, 짧을수록 좋습니다.
- 대기 시간(Waiting Time): 프로세스가 준비 큐에서 CPU를 기다리는 시간으로, 짧을수록 좋습니다.
- 응답 시간(Response Time): 요청 후 첫 응답이 시작될 때까지의 시간으로, 대화형 시스템에서 중요합니다.
스케줄러는 이러한 지표들 사이의 균형을 맞추려고 노력합니다. 예를 들어, 반환 시간을 최소화하면서 처리량을 최대화하는 것이 목표가 될 수 있습니다.
사용자 모드 & 커널 모드
보호 링(Protection Ring)
현대 CPU는 보호 링(Protection Ring)이라는 개념을 통해 여러 단계의 접근 권한을 구현합니다. 일반적으로 0~3의 번호가 부여된 링을 사용하며, 숫자가 낮을수록 높은 권한을 가집니다.
- 링 0 (커널 모드): 운영체제 커널이 실행되는 최상위 권한 모드로, 모든 하드웨어와 시스템 자원에 접근 가능합니다.
- 링 3 (사용자 모드): 일반 애플리케이션이 실행되는 제한된 권한 모드로, 직접적인 하드웨어 접근이 제한됩니다.
- 링 1, 2: 중간 수준의 권한을 가지며, 일부 운영체제나 가상화 환경에서 특수 목적으로 사용됩니다.
보호 링 구조는 악의적이거나 버그가 있는 프로그램이 시스템 전체에 영향을 주는 것을 방지합니다.
커널 모드와 사용자 모드
커널 모드(Kernel Mode)
운영체제의 핵심 부분이 실행되는 모드로, 모든 메모리와 CPU 명령어에 접근 가능하고, 하드웨어를 직접 제어할 수 있으며, 중요한 시스템 설정을 변경할 수 있고, 인터럽트 처리, 메모리 관리, 장치 제어 등의 작업을 수행할 수 있습니다. 커널 모드에서 실행되는 코드는 시스템에 심각한 영향을 줄 수 있으므로, 신중하게 설계되고 테스트되어야 합니다.
사용자 모드(User Mode)
일반 애플리케이션이 실행되는 모드로, 제한된 메모리 영역과 CPU 명령어만 접근 가능하고, 하드웨어에 직접 접근이 불가능하며, 시스템 자원은 시스템 콜을 통해 간접적으로만 사용 가능하고, 다른 프로세스의 메모리에 접근할 수 없습니다. 이러한 제한은 애플리케이션이 실수로 또는 의도적으로 시스템을 손상시키는 것을 방지합니다.
시스템 호출 (System Call)
시스템 호출은 응용 프로그램이 운영체제가 제공하는 서비스를 이용하기 위해 사용하는 인터페이스입니다. 프로그래머가 운영체제의 기능(예: 파일 입출력, 프로세스 생성)을 쉽게 사용할 수 있도록 설계된 API와 비슷한 개념입니다.
시스템 호출 동작 과정
응용 프로그램은 작업 중 커널 기능이 필요할 때 시스템 호출을 통해 사용자 모드에서 커널 모드로 전환됩니다. 이 과정에서 다음 단계가 이루어집니다.
- 응용 프로그램이 시스템 호출을 요청합니다.
- CPU가 사용자 모드에서 커널 모드로 전환합니다.
- 커널이 요청된 작업을 수행합니다.
- 작업이 완료되면 커널 모드에서 사용자 모드로 복귀합니다.
I/O 처리를 포함한 대부분의 작업은 시스템 호출을 통해 수행되며, 사용자 모드와 커널 모드 간 전환이 빈번히 발생할 수 있습니다. 이러한 전환은 모드 전환(mode switch)라고도 하며, 작업의 성격에 따라 효율적으로 관리되어야 합니다.
프로세스 및 스레드 관련 주요 시스템 호출
프로세스와 스레드 생명주기 관리에 사용되는 대표적인 시스템 호출들은 다음과 같습니다.
fork(): 새 프로세스 생성 - 현재 프로세스의 복제본 생성exec(): 새 프로그램으로 프로세스 내용 교체exit(): 프로세스 종료wait(): 자식 프로세스의 종료를 기다림- 스레드 생성 및 관리:
pthread_create(),pthread_join()(POSIX) 또는CreateThread()(Windows)
스레드 구현 방법
스레드 구현 방법은 크게 세 가지로 나뉩니다. 커널 스레드 구현(1:1 모델), 사용자 스레드 구현(1:N 모델), 그리고 하이브리드 구현(M:N 모델)입니다.
커널 수준 스레드(1:1 모델)
운영체제 커널이 직접 스레드를 관리하는 방식입니다. 각 사용자 스레드는 하나의 커널 스레드에 직접 매핑되어, 운영체제의 스케줄러가 각 스레드를 독립적으로 관리합니다. 이 모델의 큰 장점은 멀티프로세서 환경에서 진정한 병렬 실행이 가능하다는 점입니다. 예를 들어 4코어 CPU에서는 최대 4개의 스레드가 동시에 실행될 수 있습니다. 또한 한 스레드가 I/O 작업으로 블록되더라도 다른 스레드는 계속 실행될 수 있어 효율성이 높습니다. 하지만 스레드 생성과 컨텍스트 스위칭 시 커널 모드로의 전환이 필요해 오버헤드가 크고, 시스템이 관리할 수 있는 스레드 수에 제한이 있습니다. 현대의 대부분 운영체제(Windows, Linux의 NPTL, macOS)와 Java는 이 모델을 채택하고 있습니다.
사용자 수준 스레드(N:1 모델)
커널의 개입 없이 사용자 공간의 라이브러리가 스레드를 관리하는 방식입니다. 여러 사용자 스레드가 하나의 커널 스레드에 매핑되어, 운영체제는 이들을 단일 프로세스로 인식합니다. 이 방식은 스레드 생성과 전환이 커널 모드 전환 없이 이루어져 매우 가볍고 빠르며, 플랫폼에 독립적으로 구현할 수 있다는 장점이 있습니다. 그러나 결정적인 단점은 한 스레드가 블로킹 시스템 콜을 수행하면 전체 프로세스가 블록된다는 점과, 멀티코어 환경에서도 한 번에 하나의 스레드만 실행할 수 있어 병렬성의 이점을 활용할 수 없다는 점입니다. 초기 Java의 Green Threads와 GNU Portable Threads가 이 방식을 사용했습니다.
하이브리드 모델(M 모델)
앞선 두 모델의 장점을 결합하여, M개의 사용자 스레드를 N개의 커널 스레드에 매핑합니다(M ≥ N). 이 모델은 사용자 수준에서 스레드 관리의 유연성을 제공하면서도, 커널 수준에서 진정한 병렬 실행을 가능하게 합니다. 한 커널 스레드가 블록되면 다른 커널 스레드로 사용자 스레드를 마이그레이션할 수 있어 효율성이 높습니다. 그러나 구현이 매우 복잡하고, 사용자와 커널 수준 간의 조정이 어려워 대부분의 현대 운영체제는 이 모델을 포기했습니다. 예외적으로 Go 언어의 고루틴(Goroutines)과 Erlang의 경량 프로세스가 이 모델의 현대적 구현을 보여주고 있습니다.
현대 소프트웨어 개발에서는 대부분 1:1 모델이 표준으로 자리 잡았지만, 특수한 고성능 요구사항이 있는 애플리케이션에서는 여전히 다른 모델을 선택하는 경우도 있습니다. 스레드 모델의 선택은 애플리케이션의 특성, 기대하는 동시성 수준, 그리고 대상 플랫폼에 따라 달라질 수 있습니다.
이번 글에서는 운영체제의 프로세스와 스레드에 대한 핵심 개념들을 깊게 살펴보았는데요. 다음 포스팅에서는 JVM과 운영체제의 연결을 더 깊게 다뤄 보겠습니다.